Composability & Colocation w/ EdgeQL w/o Waterfalls
- Reference
Take a minute to look at the pictures below you and guess what's happening here. The language inside
the edgeql you're seeing is a mash of EdgeQL and GraphQL made just for this prototype.
The goal of this post is to gauge interest in this idea, and to see people reply on Twitter with their solutions to the problems with today's RSC world.

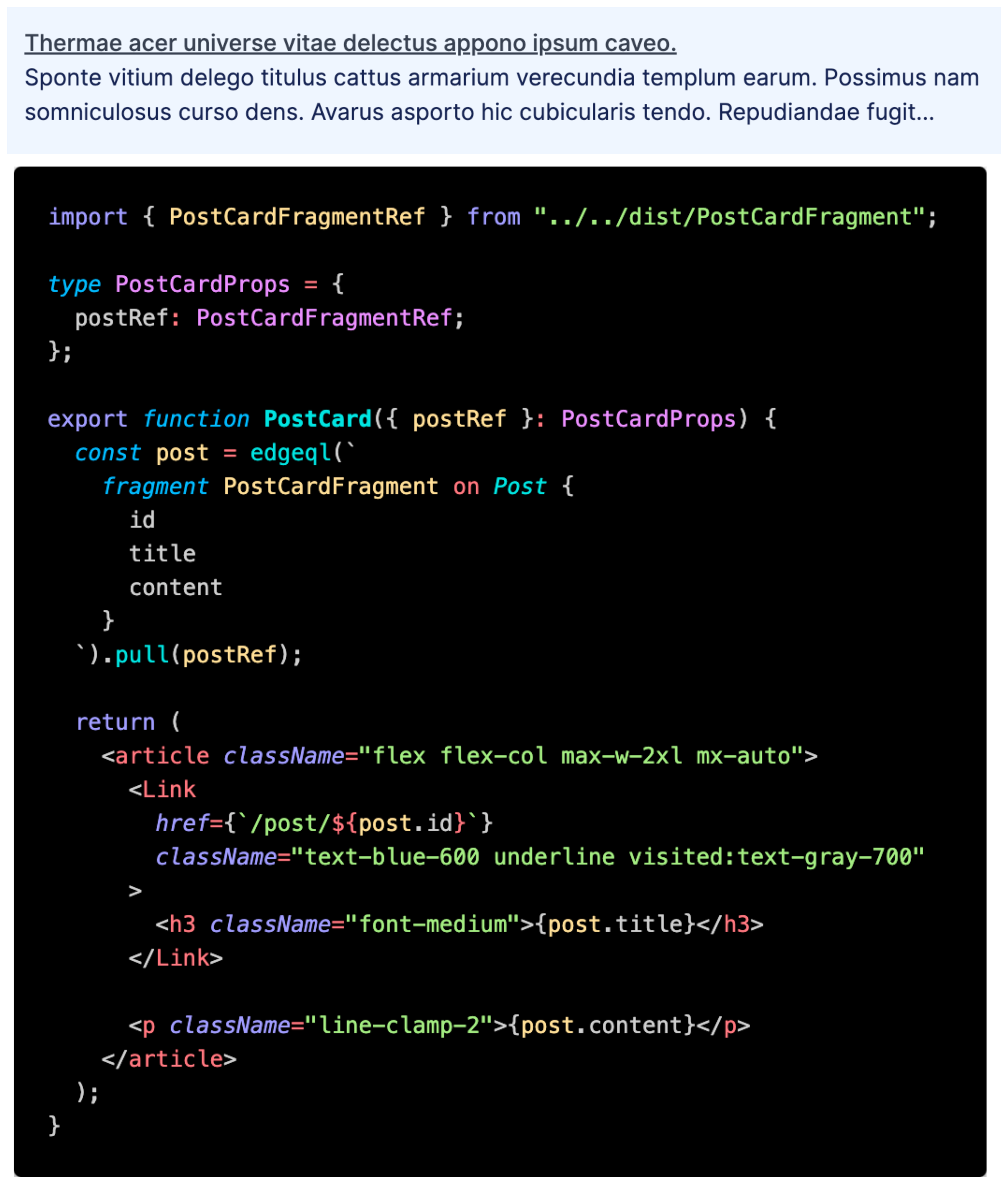
What's going on here?
- We construct a query,
PostQuery, which fetches a list of Posts, and theirids. - We then do what's called a fragment spread (
...PostCardFragment). This tells the query, "Hey, please include the selection set defined by that fragment you know about calledPostCardFragment". - We get the data back from the server, and render it.
- We render
<PostCard />and pass thepost.PostCardFragmentRefas thepostRefprop. - In the
<PostCard />component, we "pull" data out of thepostRef. Opaque to you, the developer, is that thepostRefis actually aPromisethat eventually resolves with the data your fragment asked for. The important note here is that the promise was created, and started in the component which started the query. This ensures the query starts as soon as possible and doesn't create any unnecessary waterfalls.
Another example

Breaking it down.
- We construct a query,
PostPageQuery, this time, we're fetching a single post, so we denote that with thesinglemodifier preceding the query. - We're also going to let this query take some variables, in this case, the
idof the post we want to fetch. - We select the data we need, and then we use the
filtermodifier to ensure we only get the post we want. If you've never seen EdgeDB before, you can see more about this syntax here - We then do a fragment spread, just like before, but this time, we're spreading the
CommentSectionFragmentwith the@deferdirective. - Since we're using the
@deferdirective, we're telling the server, "Hey, please don't send me this data right away, I'll ask for it later." - We wrap up this query, give it the
idvariable it needs, and send it off to EdgeDB. - The
id,title, andcontentare given back to us, and we render them. But there's another property on that object,CommentSectionFragmentwhich contains aPromisewhich will resolve the list of comments for that post.
What's the big deal?
- We're able to put our data requirements inside of the component that needs it.
- We're able to compose our data requirements together, and reuse them.
- We don't have to worry about accidental waterfalls.
- We still have the escape hatch to use
@deferif needed.
- We still have the escape hatch to use
Server Components & Data Fetching
Server components are a new feature in React that allow you to render React components on the
server. You can even write async components, wrap them in a <Suspense> component, and React will
wait for the promise to resolve before sending the HTML to the client.
Client to network waterfalls are gone, but now we have server to database waterfalls. Server to database waterfalls are significantly better than client to server waterfalls since the latency is likely much lower in your datacenter. However, we still don't have a good story around hoisting data requirements to the root of the page to ensure we don't end up shipping waterfalls to production.
You really have two options.
1. Hoist your data requirements to the root of the page manually.
type Post = { id: string; title: string; content: string }
function Page() {
const posts = await fetchPostsAndAllOfTheirFieldsThatIMayNotNeed()
return (
<main>
{posts.map((post) => {
return <PostCard key={post.id} post={post} />
})}
</main>
)
}
type PostCardProps = {
post: Post
}
function PostCard({ post }: PostCardProps) {
return (
<article>
<h1>{post.title}</h1>
<p>{post.content}</p>
</article>
)
}
The problem here is that if a child component stops needing a field, you have to remember to remove it from the parent component. This is a manual process that can be error prone and lead to performance issues. It may also lead to a very verbose manually maintained type system. Are you going to fetch every field on a type? Or are you only going to select what you need and have each component define its own type? This can get out of hand pretty quickly, and you'll likely just end up selecting every field because it's the only way to keep yourself sane.
2. Maintain colocation, but introduce waterfalls
function Page() {
const posts: number[] = await fetchPostIds()
return (
<main>
{posts.map((post) => {
return <PostCard key={post.id} post={post} />
})}
</main>
)
}
type PostCardProps = {
postId: number
}
function PostCard({ postId }: PostCardProps) {
const post = await fetchPostById(postId, ['title', 'content'])
return (
<article>
<h1>{post.title}</h1>
<p>{post.content}</p>
</article>
)
}
This one feels a lot better to use if you don't care about waterfalls. Your components get to just define their own data requirements. If you delete a component, it's data requirements go away with it.
Enter EdgeQL
EdgeQL is a new query language that is designed to be used with EdgeDB. EdgeQL offers a much more composable syntax than SQL. It also offers a much more expressive type system than SQL. You can read more about EdgeQL here.
The composability of EdgeDB is what inspired me to build this prototype. I wanted to see if I could bring the ideas of composability and colocation from Relay without any of the complexity of something like Relay + GraphQL
A quick aside on RSCs, GraphQL, and Relay
RSCs are a generalization on GraphQL, and EdgeDB is to RSC as Relay is to GraphQL
I'm a huge GraphQL / Relay fan. GraphQL is great, and Relay is great. But I think the React team has done something really intereseting with RSC. It's hard to articulate, but RSCs feel like the generalization of GraphQL. We just don't yet have the Relay equivalent for RSCs. This project could be that.
But how is RSC really a generalization of GraphQL?
- Components are the resolvers, and fragment spreads.
- The root component is your query.
RSCs are kind of like resolvers in GraphQL that happen to return JSX.
Take all of this with a grain of salt, this feeling is hard to get out of my head.
What about third party data?
There isn't a good answer here. This is where GraphQL really shines. It's data store agnostic. In this system, you can go back to the original two options. Introduce a waterfall to keep your data requirements colocated, or start the third party fetch at the root, and then pass down a promise to the component that needs it.
Back to EdgeQL and how this all works
Disclaimer: This project is a very early wip, and mostly a prototype.:
Okay, here's how it works at a very high level.
- I've written a compiler for a proprietary language that is trying to be EdgeQL with a few things sprinkled on top.
- I use the compiler to spit out EdgeQL JS Queries that look like this.
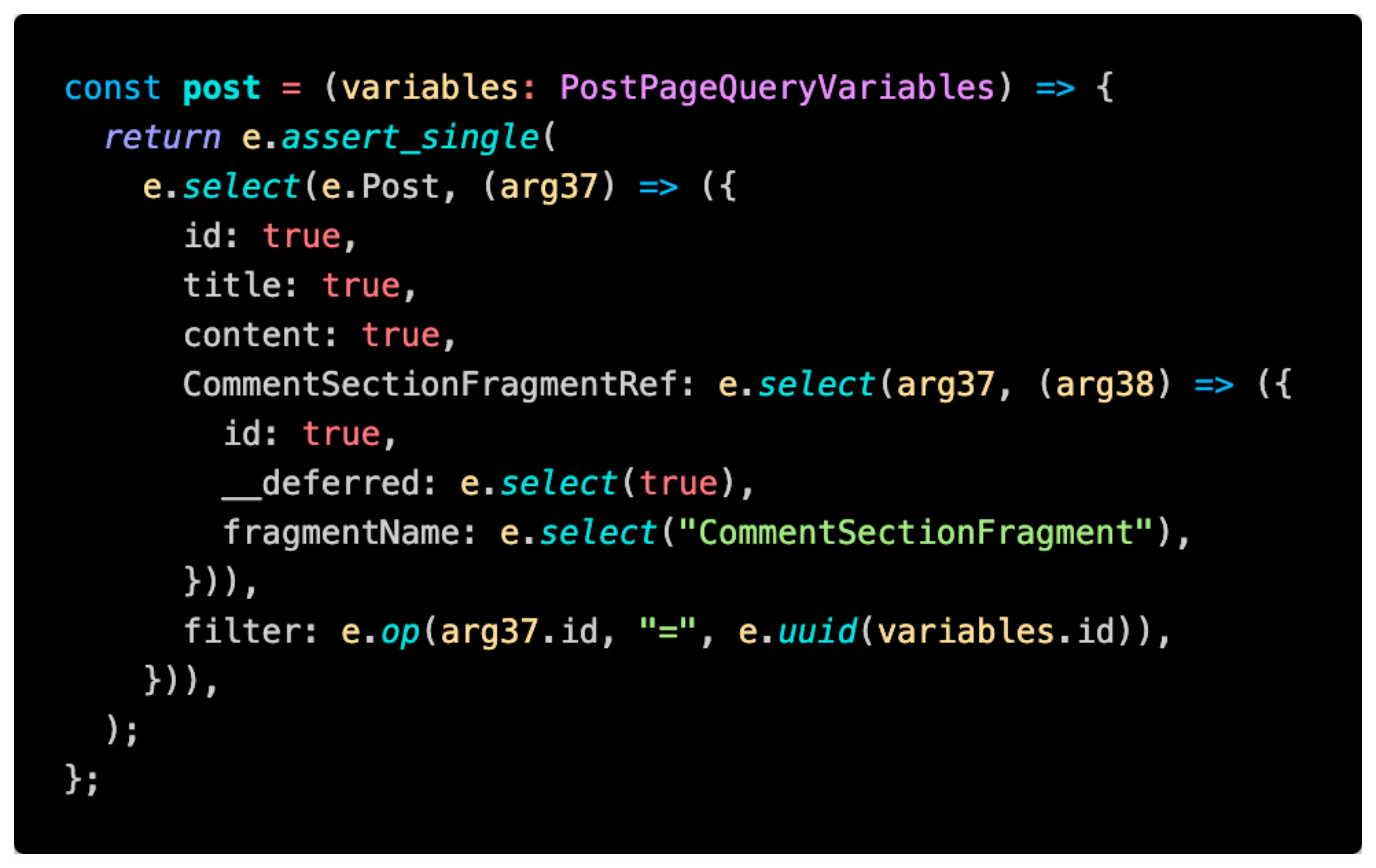
- When you run the query, this function is run with the variables you pass in. Notice that I'm not actually fetching the comments here. Just asking for some metadata so I can use it later.
- I then take the result, and convert all of those
@deferdirectives into Promises via a utility function that crawls the resulting object and replaced the__deferredobjects with promises.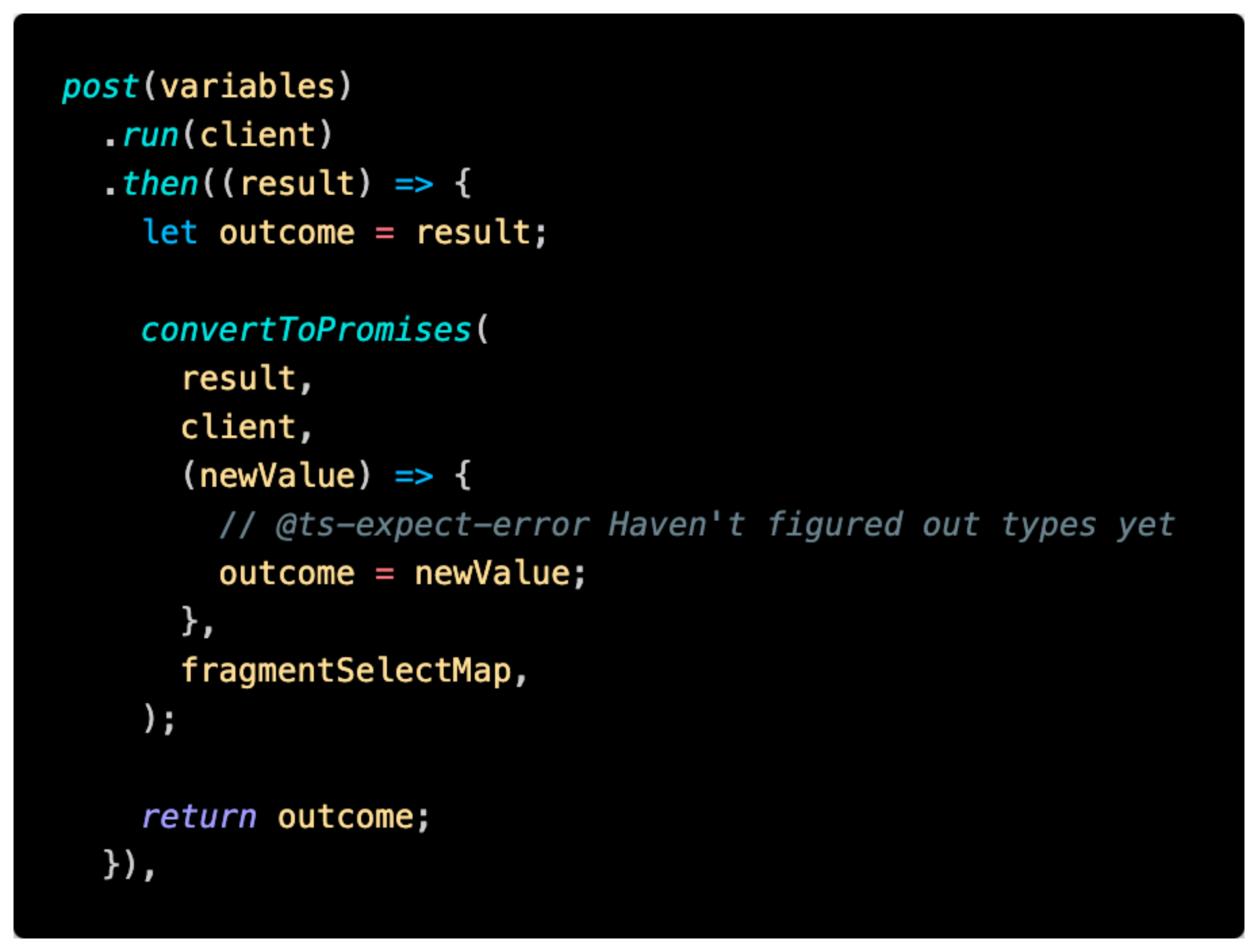
This is really the core of the project, if you're interested in seeing how the rest of it works, feel free to check out the source code
Realtime type safety
Here's a video to show you how fast you get updated types in VSCode. You get all of the important things.
- Types for query result
- Types for fragment result
- Types for fragment refs
- Types for query variables
What's next?
I don't know. If you're interested, please reach out to me on twitter